Notation. For symbol definitions, see the notation vignette.
Overview
The aim of this vignette is show how to perform correct validation
tests using closest-not-yet-treated control groups using
childpen.
Simulate data
The package has a built in simulation function to draw data resembling child penalty studies.
library(childpen)
data <- simulate_data(n_individuals = 5000, treatment_groups = 24:28)
data |> tibble()
#> # A tibble: 40,000 × 5
#> id female age D Y
#> <int> <int> <int> <int> <dbl>
#> 1 1 1 20 24 36267.
#> 2 1 1 21 24 46761.
#> 3 1 1 22 24 40172.
#> 4 1 1 23 24 61655.
#> 5 1 1 24 24 39286.
#> 6 1 1 25 24 52229.
#> 7 1 1 26 24 39057.
#> 8 1 1 27 24 59584.
#> 9 2 1 20 28 50250.
#> 10 2 1 21 28 52739.
#> # ℹ 39,990 more rowsThe correct validation tests
See the estimation vignette for an
explainer on the
comparisons in childpen. Recall that
is the treatment group,
is the target age, and
is the closest not-yet-treated control group. Recall that the control
group is
,
the cohort whose first birth is one year after the target age.
Assume that when presenting results, post-treatment, you report estimates for event times . Then, for each treatment group you use 3 different control groups in post-treatment estimation. As the identification assumptions (e.g., parallel trends for DID) must hold for each point-estimate separately, this implies that it must hold within each treatment-control pair.
The above argument means that the validation tests should be done
separately by treatment-control combinations. Returning to the above
example, if you want to show results for
then you need to conduct pre-trend analysis for 3 different control
groups. This is done automatically in the childpen package,
as we show below.
For completeness, the validation tests are:
- Difference-in-differences (DID) estimates the average treatment effect (ATE) in pre-periods
- Triple differences (TD) estimates the gender gap in the ATE in pre-periods
- Normalized triple differences (NTD) estimates the gender gap in normalized effects in pre-periods
Multiple treatment group analysis
We will now do the main heavy lifting. We run the main estimation
function, multiple_treatment_group_analysis(). Set
periods_pre to the number of pre-treatment periods for
which you want to conduct validation tests. As an example, we will
examine two periods pre-treatment. Since we set the number of periods in
the post-treatment to 2 using periods_post, this will
report validation tests separately for 3 control groups, as discussed
above.
res = multiple_treatment_group_analysis(data = data,
treatment_groups = 24:25, # which treatment groups to run in the analysis
periods_post = 2, # estimate results for post periods 0:2
periods_pre = 2, # estimate pre-trend diagnostics, set to NULL to omit from estimation
max_age = 40, # dont estimate results if age is above 40
min_age = 20, # dont estimate results if age is below 20
pre = 1, # use 1 period before treatment, can make further away if anticipation is concern
verbose = FALSE # set to TRUE to output progress (i like to time loops) set to FALSE to omit messages
)Examining results of validation tests
As a first pass, lets see the results.
res |> tibble()
#> # A tibble: 270 × 16
#> d dp a event_time estimand method est se ci_l
#> <int> <dbl> <int> <int> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 24 25 24 0 APO DID_Female 5.42e+4 7.95e+2 5.27e+4
#> 2 24 25 24 0 APO DID_Male 6.23e+4 8.82e+2 6.06e+4
#> 3 24 25 24 0 ATE DID_Female -1.30e+4 7.02e+2 -1.43e+4
#> 4 24 25 24 0 ATE DID_Male -3.71e+3 8.27e+2 -5.34e+3
#> 5 24 25 24 0 theta DID_Female -2.39e-1 1.03e-2 -2.59e-1
#> 6 24 25 24 0 theta DID_Male -5.96e-2 1.27e-2 -8.45e-2
#> 7 24 25 24 0 ATE TD -9.25e+3 1.08e+3 -1.14e+4
#> 8 24 25 24 0 theta NTD_Conv -1.79e-1 1.64e-2 -2.12e-1
#> 9 24 25 24 0 Delta_rho NTD_New -1.66e-1 1.59e-2 -1.97e-1
#> 10 24 25 24 0 APO TD_Null 5.05e+4 1.15e+3 4.83e+4
#> # ℹ 260 more rows
#> # ℹ 7 more variables: ci_h <dbl>, t <dbl>, p <dbl>, n_female_treat <int>,
#> # n_female_control <int>, n_male_treat <int>, n_male_control <int>Focusing on , lets examine pre-trends. We will start with DID of females. Generally, valid pre-trend validation tests would behave such that the confidence intervals include 0, and there is no obvious trend in the pre-period, and there is no systematic difference between control groups. A valid pre-trend test shows point estimates near zero with confidence intervals covering zero and no systematic trend across pre-treatment event times.
Note that in the plot below I define control_offset as
the difference between the control group
and the treatment group
.
E.g., for
and
,
i.e., the closest not-yet-treated control group at event time
,
I set control offset to 1.
Ribbons present 95% CI based on standard errors clustered at the individual level.
res |>
filter(d == 24,
a < d,
estimand == "ATE",
method == "DID_Female") |>
mutate(control_offset = dp - d,
control_offset = factor(control_offset)) |>
ggplot(aes(x = event_time, y = est, ymin = ci_l, ymax = ci_h, color = control_offset, fill = control_offset)) +
geom_ribbon(alpha = .15, color = NA) + geom_point() + geom_line() +
scale_x_continuous(breaks = -3:-2) +
facet_grid(cols = vars(control_offset))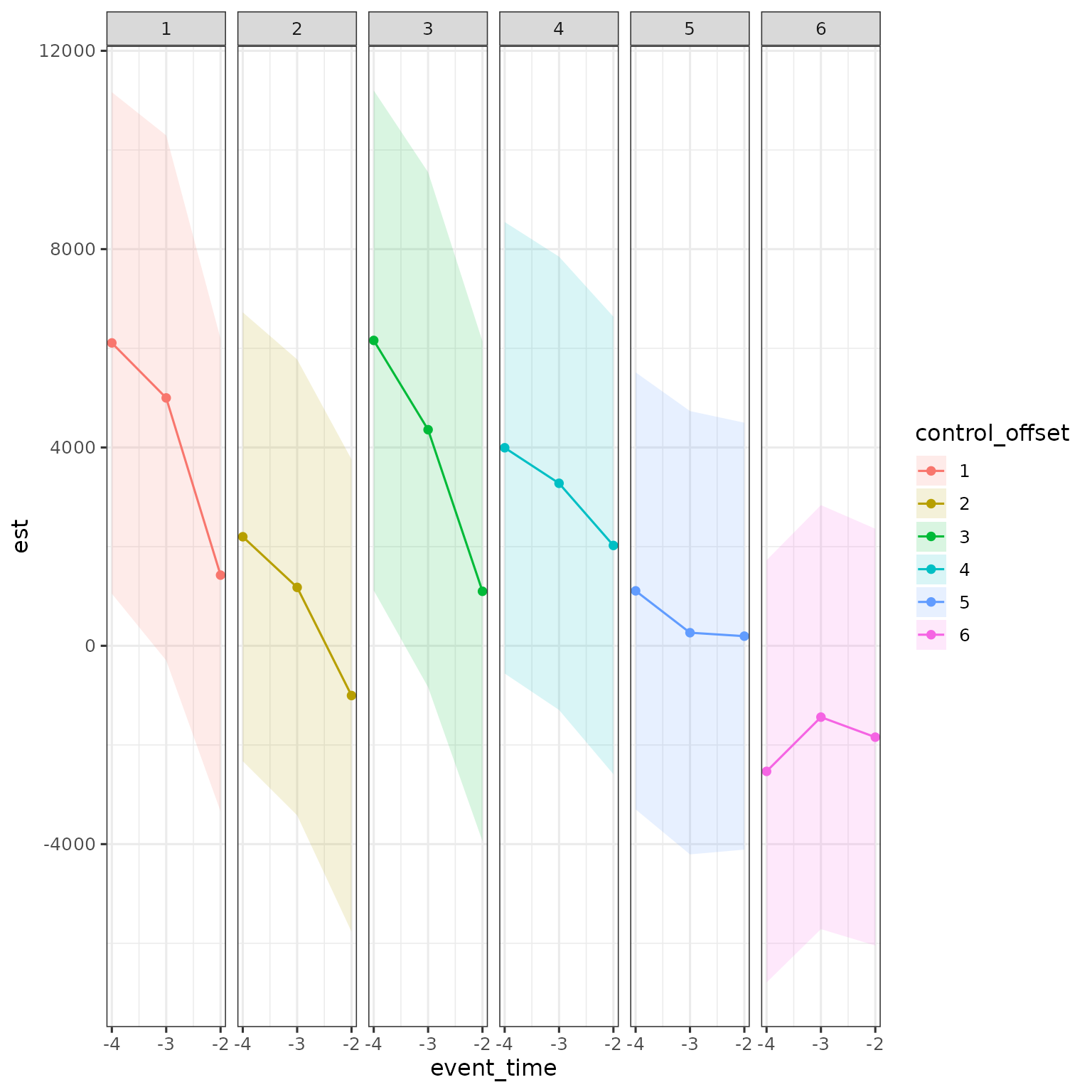
Although this would be hard to look at, we can put all control offsets on same plot.
res |>
filter(d == 24,
a < d,
estimand == "ATE",
method == "DID_Female") |>
mutate(control_offset = dp - d,
control_offset = factor(control_offset)) |>
ggplot(aes(x = event_time, y = est, ymin = ci_l, ymax = ci_h, color = control_offset, fill = control_offset)) +
geom_ribbon(alpha = .15, color = NA) + geom_point() + geom_line() +
scale_x_continuous(breaks = -3:-2)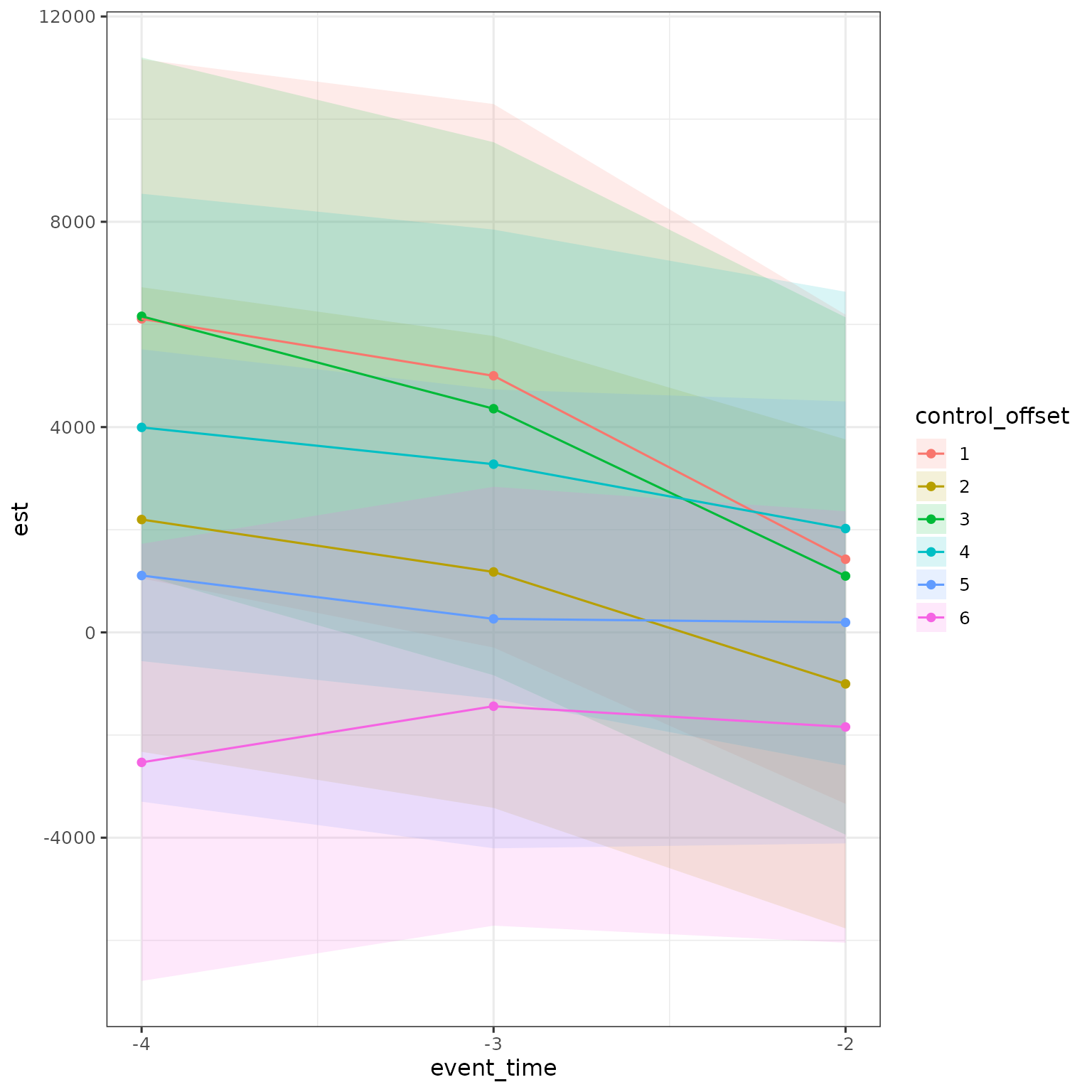
Can do this for multiple treatment groups at same time
res |>
filter(a < d,
estimand == "ATE",
method == "DID_Female") |>
mutate(control_offset = dp - d,
control_offset = factor(control_offset)) |>
ggplot(aes(x = event_time, y = est, ymin = ci_l, ymax = ci_h, color = control_offset, fill = control_offset)) +
geom_ribbon(alpha = .15, color = NA) + geom_point() + geom_line() +
scale_x_continuous(breaks = -3:-2) +
facet_grid(cols = vars(d))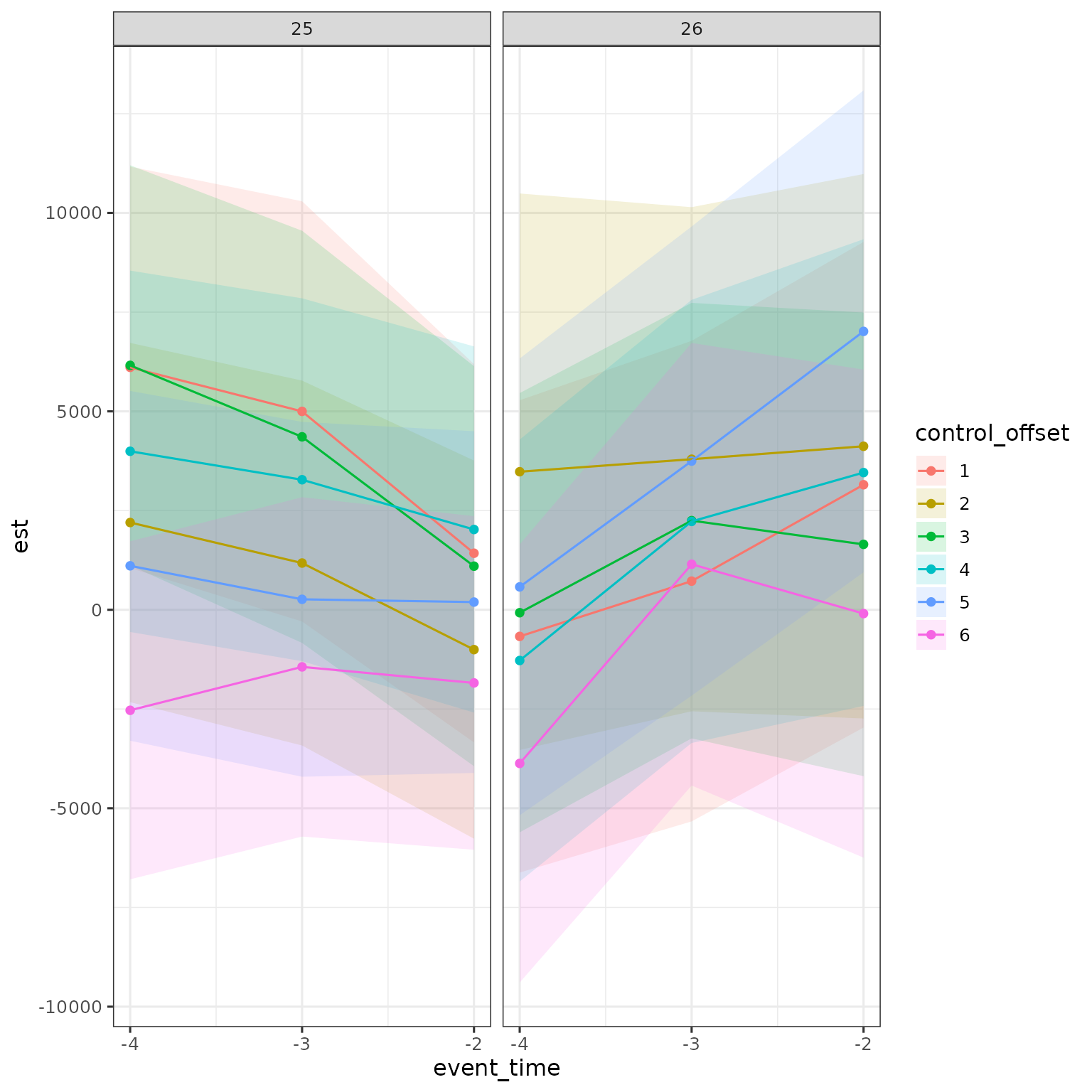
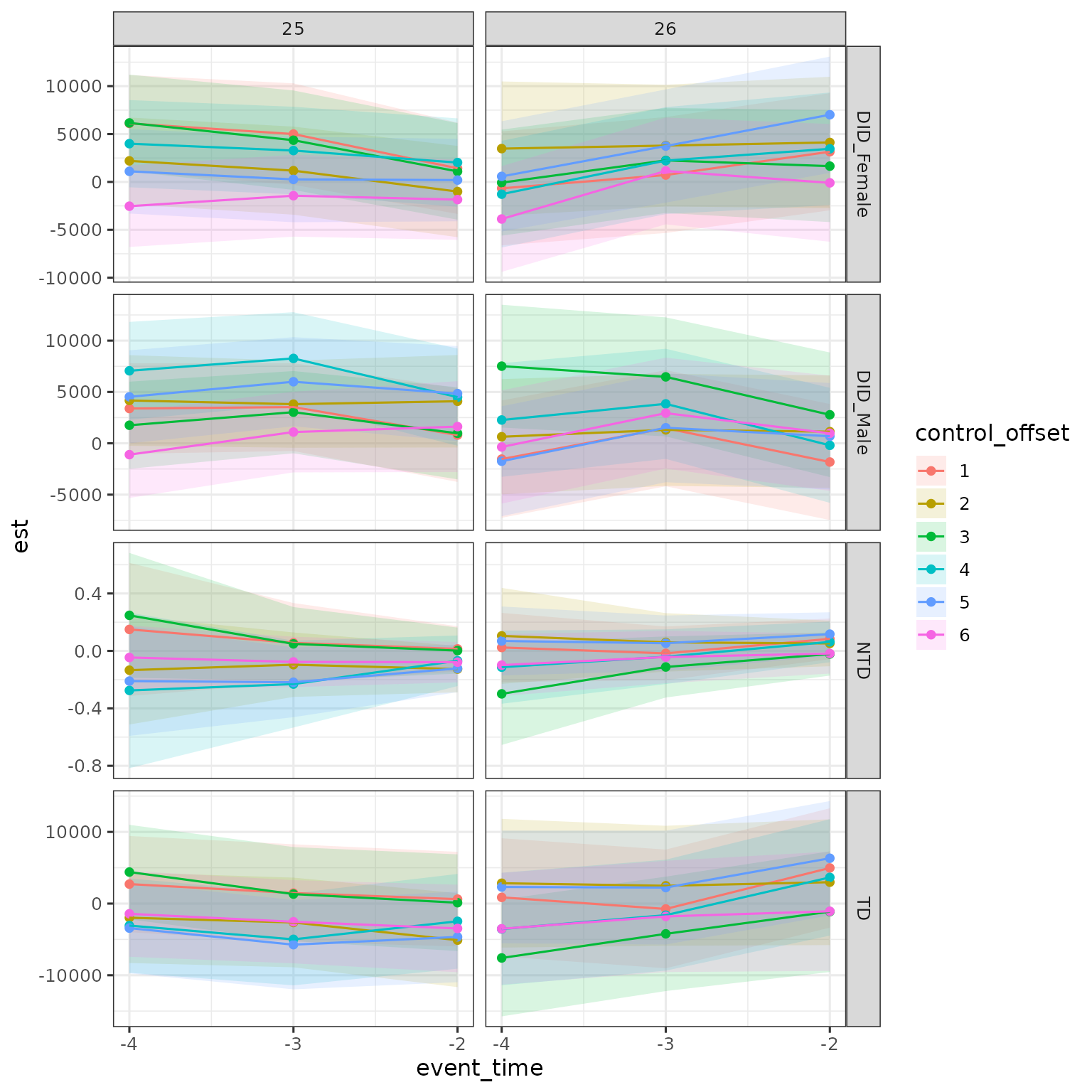
Finally, can do this for all methods.
res |>
filter(a < d,
estimand == "ATE" & (method == "DID_Female" | method == "DID_Male" | method == "TD") |
estimand == "theta" & method == "NTD_Conv") |>
mutate(control_offset = dp - d,
control_offset = factor(control_offset)) |>
ggplot(aes(x = event_time, y = est, ymin = ci_l, ymax = ci_h, color = control_offset, fill = control_offset)) +
geom_ribbon(alpha = .15, color = NA) + geom_point() + geom_line() +
scale_x_continuous(breaks = -3:-2) +
facet_grid(cols = vars(d), rows = vars(method), scales = "free")